ChatGPT, GPT-4, Claude, Gemini 등 요즘 화제의 AI 챗봇들은 모두 LLM(대규모 언어 모델)을 기반으로 합니다.
그중에서도 GPT(Generative Pretrained Transformer)는 이름 그대로 Transformer 구조를 기반으로 만들어진 모델이죠.
하지만 “GPT는 트랜스포머와 어떻게 다른가?”, “GPT의 구조는 정확히 어떻게 생겼을까?”
이런 궁금증을 가진 분들을 위해, 이번 글에서는 GPT 모델의 기본 구조를 일반 트랜스포머와의 차이점을 중심으로 자세히 설명합니다.
GPT는 Transformer의 디코더(Decoder)만 사용한다
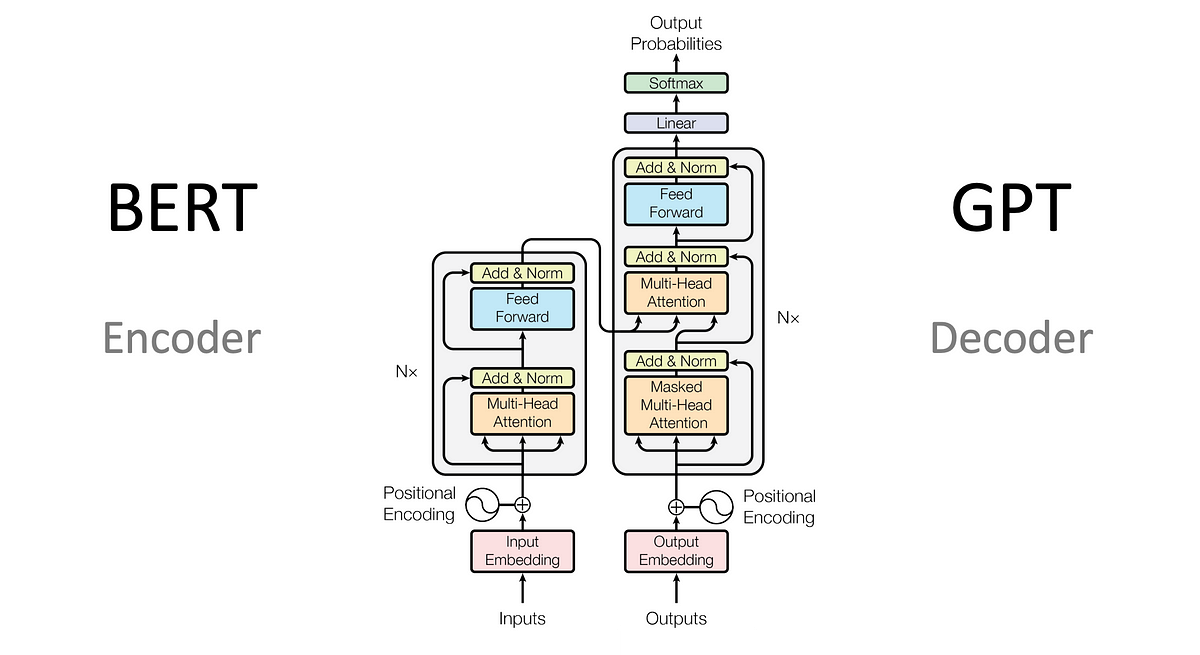
2017년 구글의 논문 《Attention Is All You Need》에서 처음 등장한 트랜스포머는 크게 두 부분으로 구성됩니다:
- Encoder (인코더): 입력 문장의 의미를 이해하고 표현
- Decoder (디코더): 인코딩된 정보를 바탕으로 출력 문장을 생성
예를 들어, 영어→한국어 번역에서는 Encoder가 영어를 이해하고, Decoder가 한국어로 바꾸는 역할을 하죠.
하지만 GPT는 번역기가 아닌, “문장 생성기”입니다.
따라서 입력 문장을 인코딩할 필요가 없고, 디코더만 남긴 구조를 사용합니다.
GPT의 전체 구조 한눈에 보기
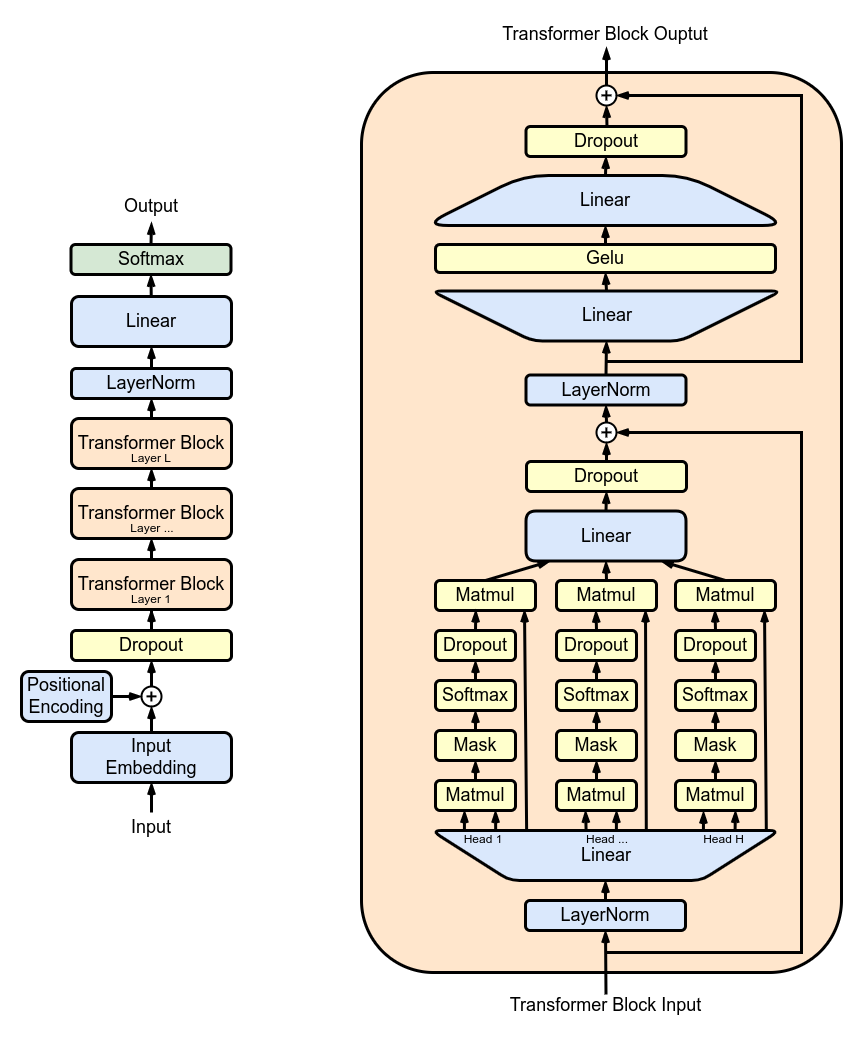
GPT의 기본 구조는 단순하지만 강력합니다.
[입력 토큰]
↓
[토큰 임베딩 + 위치 인코딩]
↓
[Transformer Block × N]
↓
[출력층 (Linear + Softmax)]각 Transformer Block은 다음 두 가지 핵심 모듈로 이루어집니다:
- Masked Multi-Head Self-Attention
- Feed Forward Network (FFN)
그리고 각 층에는 Residual Connection과 Layer Normalization이 포함됩니다.
일반 Transformer와 GPT의 차이
| 구분 | 일반 Transformer | GPT (Decoder-only) |
|---|---|---|
| 구조 | Encoder + Decoder | Decoder만 사용 |
| Attention 방식 | Self + Cross | Masked Self-Attention |
| 입력 | 문장쌍(예: 번역) | 단일 시퀀스(텍스트 생성) |
| 포지셔널 인코딩 | Sine/Cosine 방식 | 학습형(learned) 또는 RoPE 방식 |
| LayerNorm 위치 | Post-Norm(원 논문) | Pre-Norm(안정성 개선) |
| 학습 목표 | 입력-출력 매핑 | 다음 단어 예측 |
| 대표 모델 | BERT, T5, BART | GPT 시리즈 (ChatGPT 등) |
즉, GPT는 트랜스포머의 디코더 구조를 자기회귀(autoregressive) 언어 생성에 맞게 단순화한 버전입니다.
GPT의 입력과 출력 과정
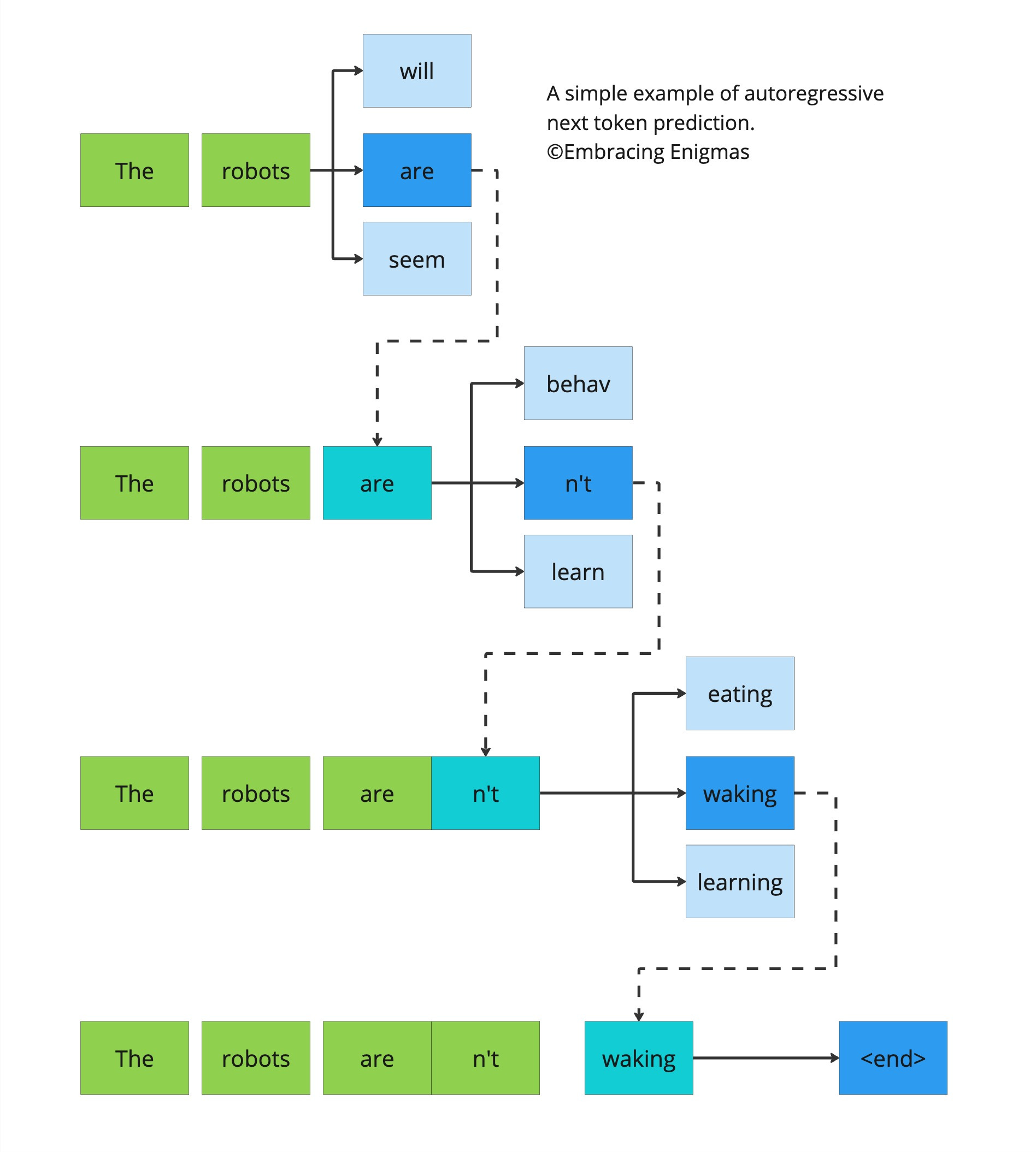
GPT는 이전까지의 단어를 보고 다음 단어를 예측하는 구조입니다.
- 입력 토큰화
예: “오늘 날씨가 좋” →[100, 392, 12, 94] - 임베딩 + 포지셔널 인코딩
각 토큰을 벡터화하고, 순서 정보를 더함 - Masked Multi-Head Self-Attention
각 단어가 “자신보다 앞선 단어”까지만 참고하도록 마스크 적용 - Feed Forward Network (FFN)
어텐션 결과를 비선형 변환 - 출력층 (Softmax)
다음 단어 확률 계산 → “다”의 확률이 가장 높으면 선택
이 과정을 반복하면서 문장을 한 단어씩 생성합니다.
GPT 블록의 내부 구조
GPT의 한 층(Transformer Block)은 다음과 같은 순서를 가집니다.
입력 (x)
↓
LayerNorm
↓
Masked Multi-Head Self-Attention
↓
Residual Add
↓
LayerNorm
↓
Feed Forward Network (FFN)
↓
Residual Add핵심 특징
- Pre-Norm 구조: 학습 안정성을 높임
- Masked Attention: 미래 단어를 참조하지 않음
- Residual Add: 깊은 네트워크에서도 그라디언트 손실 방지
GPT의 학습 목표: 다음 단어 예측 (Next Token Prediction)
GPT는 문맥을 보고 다음 단어를 맞추는 확률모델입니다.
이 확률을 최대화하도록 학습하며, Cross Entropy Loss로 평가합니다.
즉, GPT는 “다음 단어 예측(next token prediction)”을 수십억 번 반복하면서
언어의 패턴과 문맥을 스스로 학습합니다.
GPT 계열 모델의 발전
| 모델 | 발표연도 | 특징 | 파라미터 수 |
|---|---|---|---|
| GPT-1 | 2018 | 트랜스포머 디코더 기반 언어모델 시초 | 117M |
| GPT-2 | 2019 | Zero-shot 생성 가능성 제시 | 1.5B |
| GPT-3 | 2020 | Few-shot 학습(In-context Learning) | 175B |
| GPT-3.5 | 2022 | RLHF(인간 피드백 학습) 도입 | 약 175B |
| GPT-4 | 2023 | 멀티모달(이미지+텍스트) 지원, 안정성·추론 능력 향상 | 비공개 (수천억~조 단위 추정) |
| GPT-5 | 2025 | 멀티모달+에이전트형 구조, 장기 메모리·도구 사용·지속적 학습 지원 | 비공개 (GPT-4 대비 수 배 규모 추정) |
GPT-4는 기본적인 디코더 구조를 유지하면서, 내부적으로 멀티모달 처리 계층, 안정화 모듈, 효율적 어텐션(FastAttention)을 추가했습니다.
GPT vs 일반 Transformer 요약 비교
| 항목 | Transformer | GPT |
|---|---|---|
| 구조 | Encoder + Decoder | Decoder-only |
| 어텐션 | Self + Cross | Masked Self |
| 입력 방식 | 쌍방향 문장 | 단방향 시퀀스 |
| 학습 목적 | 번역/요약 | 언어 생성 |
| 출력 | 완성된 문장 | 다음 단어 |
| 대표 예시 | BERT, T5, BART | GPT-3, ChatGPT, GPT-4 |
결론
GPT는 Transformer 구조의 “디코더”만 사용하는 자기회귀 언어 모델입니다.
즉, GPT는 트랜스포머의 어텐션 메커니즘을 그대로 유지하면서,
다음 단어를 예측하는 단순한 목표로 언어 생성 능력을 극대화한 구조예요.
핵심 요약
- GPT는 Transformer 디코더 기반 모델이다.
- Masked Self-Attention을 사용하여 한 방향으로 문맥을 읽는다.
- 학습 목표는 “다음 단어 예측(next token prediction)”.
'AI·기술 > AI 개발·엔지니어링' 카테고리의 다른 글
| 트랜스포머(Transformer) 모델 구조: 어텐션·멀티헤드·포지셔널 인코딩·FFN·정규화·마스킹까지 (0) | 2025.11.10 |
|---|---|
| LLM이란? ChatGPT의 핵심 기술, 대규모 언어 모델 이해하기 (0) | 2025.11.09 |